> For the complete documentation index, see [llms.txt](https://javascriptuse.gitbook.io/javascript/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://javascriptuse.gitbook.io/javascript/advanced/a-graphql-sqlite-sequelize-full-ok.md).
# A GraphQL Sqlite, sequelize Full (ok)
## Example 1 ()
{% file src="/files/YbWRS8rNBmnpHVEN3UsD" %}
{% file src="/files/DyT2ldHMh2lHyTCXStsb" %}
### — Step 1 getUsers
package.json
```json
{
"name": "sequelize",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"dev": "nodemon src/server.ts"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": "",
"dependencies": {
"express": "^4.21.2",
"mysql2": "^3.12.0",
"sequelize": "^6.37.5"
},
"devDependencies": {
"@types/dotenv": "^6.1.1",
"@types/express": "^5.0.0",
"@types/node": "^22.10.7",
"dotenv": "^16.4.7",
"nodemon": "^3.1.9",
"ts-node": "^10.9.2",
"typescript": "^5.7.3"
}
}
```
.env
```properties
DB_NAME="database_test"
DB_USER="root"
DB_PASS=""
DB_HOST="localhost"
```
{% file src="/files/kdObDubocBceAVlcRuTx" %}
src\server.ts
```typescript
import app from './app';
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Servidor rodando na porta ${PORT}`);
console.log(`Documentação disponível em http://localhost:${PORT}/api/docs`);
});
```
src\app.ts
```typescript
import express from 'express';
import userRoutes from './routes/userRoutes';
import sequelize from './config/database';
const app = express();
app.use(express.json());
app.use('/api', userRoutes);
sequelize.sync()
.then(() => {
console.log('DB Connected');
})
.catch((error: any) => {
console.error('Erro ao conectar ao banco de dados:', error);
});
export default app;
```
src\routes\userRoutes.ts
```typescript
import { Router } from 'express';
import { getUsers } from '../controllers/userController';
const router = Router();
router.get('/users', getUsers);
export default router;
```
src\controllers\userController.ts
```typescript
import { Request, Response } from 'express';
import User from '../models/user';
import { buildUserFilters } from './Filters/UserFilters';
import { UserDTO } from './Interfaces/getUserInterface';
import { UserQueryParams } from './Interfaces/UserQueryParams';
import { mapUserToDTO } from '../mappers/userMapper';
import { Mapper } from '../mappers/mapper';
export const getUsers = async (req: Request, res: Response): Promise => {
try {
const filters = buildUserFilters(req.query as UserQueryParams);
const users = await User.findAll({ where: filters });
const userDTOs: UserDTO[] = Mapper.toDTOArray(users, mapUserToDTO);
res.status(200).json(userDTOs);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
```
src\controllers\Filters\UserFilters.ts
```typescript
import { Op } from 'sequelize';
import { UserQueryParams } from '../Interfaces/UserQueryParams';
export const buildUserFilters = ({ nome, idadeMin, idadeMax, email }: UserQueryParams) => {
const filters: any = {};
if (nome) {
filters.nome = { [Op.like]: `%${nome}%` };
}
// Filtro por faixa de idade, se definido
const minAge = idadeMin ? parseInt(idadeMin, 10) : undefined;
const maxAge = idadeMax ? parseInt(idadeMax, 10) : undefined;
if (minAge !== undefined || maxAge !== undefined) {
filters.idade = {};
if (minAge !== undefined) filters.idade[Op.gte] = minAge;
if (maxAge !== undefined) filters.idade[Op.lte] = maxAge;
}
// Filtro por email
if (email) { // Corrigido aqui
filters.email = { [Op.like]: `%${email}%` };
}
return filters;
}
```
src\controllers\Interfaces\getUserInterface.ts
```typescript
export interface UserDTO {
id: string;
nome: string;
email: string;
idade: number | undefined;
ativo: boolean | undefined;
}
```
src\controllers\Interfaces\UserQueryParams.ts
```typescript
export interface UserQueryParams {
nome?: string;
email?: string;
idadeMin?: string;
idadeMax?: string;
}
```
src\mappers\mapper.ts
```typescript
export class Mapper {
static toDTO(entity: T, mapperFunction: (entity: T) => U): U {
return mapperFunction(entity);
}
static toDTOArray(entities: T[], mapperFunction: (entity: T) => U): U[] {
return entities.map(mapperFunction);
}
}
```
src\mappers\userMapper.ts
```typescript
import User from "../models/user";
import { UserDTO } from "../controllers/Interfaces/getUserInterface";
export const mapUserToDTO = (user: User): UserDTO => ({
id: user.id,
nome: user.nome,
email: user.email,
idade: user.idade,
ativo: user.ativo,
});
```
src\models\user.ts
```typescript
import { DataTypes, Model } from 'sequelize';
import sequelize from '../config/database';
class User extends Model {
public id!: string;
public nome!: string;
public email!: string;
public idade?: number;
public ativo!: boolean;
}
User.init({
id: {
type: DataTypes.UUID,
defaultValue: DataTypes.UUIDV4,
primaryKey: true,
unique: true,
},
nome: {
type: DataTypes.STRING,
allowNull: false,
validate: {
len: [3, 255],
},
},
email: {
type: DataTypes.STRING,
allowNull: false,
unique: true,
validate: {
isEmail: true,
},
},
idade: {
type: DataTypes.INTEGER.UNSIGNED,
allowNull: true,
},
ativo: {
type: DataTypes.BOOLEAN,
defaultValue: true,
},
}, {
sequelize,
modelName: 'User',
tableName: 'users',
timestamps: true,
});
export default User;
```
src\config\database.ts
```typescript
import { Sequelize } from 'sequelize';
import dotenv from 'dotenv';
dotenv.config();
const sequelize = new Sequelize(process.env.DB_NAME!, process.env.DB_USER!, process.env.DB_PASS!, {
host: process.env.DB_HOST,
dialect: 'mysql'
});
export default sequelize;
```
### — Step 2 getUserById
src\routes\userRoutes.ts
```typescript
import { Router } from 'express';
import { getUsers, getUserById } from '../controllers/userController';
const router = Router();
router.get('/users', getUsers);
router.get('/users/:id', getUserById);
export default router;
```
src\controllers\userController.ts
```typescript
import { Request, Response } from 'express';
import User from '../models/user';
import { buildUserFilters } from './Filters/UserFilters';
import { UserDTO } from './Interfaces/getUserInterface';
import { UserQueryParams } from './Interfaces/UserQueryParams';
import { mapUserToDTO } from '../mappers/userMapper';
import { Mapper } from '../mappers/mapper';
export const getUsers = async (req: Request, res: Response): Promise => {
try {
const filters = buildUserFilters(req.query as UserQueryParams);
const users = await User.findAll({ where: filters });
const userDTOs: UserDTO[] = Mapper.toDTOArray(users, mapUserToDTO);
res.status(200).json(userDTOs);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const getUserById = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'Usuário não encontrado' });
return;
}
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(200).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuário', details: (error as Error).message });
}
};
```
### — Step 3 createUser
src\controllers\userController.ts
```typescript
import { Request, Response } from 'express';
import User from '../models/user';
import { buildUserFilters } from './Filters/UserFilters';
import { UserDTO } from './Interfaces/getUserInterface';
import { UserQueryParams } from './Interfaces/UserQueryParams';
import { mapUserToDTO } from '../mappers/userMapper';
import { Mapper } from '../mappers/mapper';
export const getUsers = async (req: Request, res: Response): Promise => {
try {
const filters = buildUserFilters(req.query as UserQueryParams);
const users = await User.findAll({ where: filters });
const userDTOs: UserDTO[] = Mapper.toDTOArray(users, mapUserToDTO);
res.status(200).json(userDTOs);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const getUserById = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'Usuário não encontrado' });
return;
}
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(200).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuário', details: (error as Error).message });
}
};
export const createUser = async (req: Request, res: Response): Promise => {
try {
const { nome, email, idade, ativo } = req.body;
const user = await User.create({ nome, email, idade, ativo });
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(201).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao criar usuário', details: (error as Error).message });
}
};
```
src\routes\userRoutes.ts
```typescript
import { Router } from 'express';
import { getUsers, getUserById, createUser } from '../controllers/userController';
const router = Router();
router.get('/users', getUsers);
router.get('/users/:id', getUserById);
router.post('/users', createUser);
export default router;
```
### — Step 4 updateUser
src\routes\userRoutes.ts
```typescript
import { Router } from 'express';
import { getUsers, getUserById, createUser, updateUser } from '../controllers/userController';
const router = Router();
router.get('/users', getUsers);
router.get('/users/:id', getUserById);
router.post('/users', createUser);
router.put('/users/:id', updateUser);
export default router;
```
src\controllers\userController.ts
```typescript
import { Request, Response } from 'express';
import User from '../models/user';
import { buildUserFilters } from './Filters/UserFilters';
import { UserDTO } from './Interfaces/getUserInterface';
import { UserQueryParams } from './Interfaces/UserQueryParams';
import { mapUserToDTO } from '../mappers/userMapper';
import { Mapper } from '../mappers/mapper';
export const getUsers = async (req: Request, res: Response): Promise => {
try {
const filters = buildUserFilters(req.query as UserQueryParams);
const users = await User.findAll({ where: filters });
const userDTOs: UserDTO[] = Mapper.toDTOArray(users, mapUserToDTO);
res.status(200).json(userDTOs);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const getUserById = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'Usuário não encontrado' });
return;
}
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(200).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuário', details: (error as Error).message });
}
};
export const createUser = async (req: Request, res: Response): Promise => {
try {
const { nome, email, idade, ativo } = req.body;
const user = await User.create({ nome, email, idade, ativo });
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(201).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao criar usuário', details: (error as Error).message });
}
};
export const updateUser = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const { nome, email, idade, ativo } = req.body;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'Usuário não encontrado' });
return;
}
const userDTO: UserDTO = Mapper.toDTO(await user.update({ nome, email, idade, ativo }), mapUserToDTO);
res.status(200).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao atualizar usuário', details: (error as Error).message });
}
};
```
### — Step 5 deleteUser
src\routes\userRoutes.ts
```typescript
import { Router } from 'express';
import { getUsers, getUserById, createUser, updateUser, deleteUser } from '../controllers/userController';
const router = Router();
router.get('/users', getUsers);
router.get('/users/:id', getUserById);
router.post('/users', createUser);
router.put('/users/:id', updateUser);
router.delete('/users/:id', deleteUser);
export default router;
```
src\controllers\userController.ts
```typescript
import { Request, Response } from 'express';
import User from '../models/user';
import { buildUserFilters } from './Filters/UserFilters';
import { UserDTO } from './Interfaces/getUserInterface';
import { UserQueryParams } from './Interfaces/UserQueryParams';
import { mapUserToDTO } from '../mappers/userMapper';
import { Mapper } from '../mappers/mapper';
export const getUsers = async (req: Request, res: Response): Promise => {
try {
const filters = buildUserFilters(req.query as UserQueryParams);
const users = await User.findAll({ where: filters });
const userDTOs: UserDTO[] = Mapper.toDTOArray(users, mapUserToDTO);
res.status(200).json(userDTOs);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const getUserById = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'User not found' });
return;
}
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(200).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuário', details: (error as Error).message });
}
};
export const createUser = async (req: Request, res: Response): Promise => {
try {
const { nome, email, idade, ativo } = req.body;
const user = await User.create({ nome, email, idade, ativo });
const userDTO: UserDTO = Mapper.toDTO(user, mapUserToDTO);
res.status(201).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Erro ao criar usuário', details: (error as Error).message });
}
};
export const updateUser = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const { nome, email, idade, ativo } = req.body;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'User not found' });
return;
}
const userDTO: UserDTO = Mapper.toDTO(await user.update({ nome, email, idade, ativo }), mapUserToDTO);
res.status(200).json(userDTO);
} catch (error) {
res.status(500).json({ message: 'Error updating user', details: (error as Error).message });
}
};
export const deleteUser = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const user = await User.findByPk(id);
if (!user) {
res.status(404).json({ message: 'User not found' });
return;
}
await user.destroy();
res.status(204).send();
} catch (error) {
res.status(500).json({ message: 'Error deleting user', details: (error as Error).message });
}
};
```
## Practice 1
package.json
```json
{
"name": "sequelize",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"dev": "nodemon src/server.ts"
},
"dependencies": {
"@types/dotenv": "^8.2.3",
"@types/express": "^5.0.0",
"@types/node": "^22.10.7",
"dotenv": "^16.4.7",
"express": "^4.21.2",
"mysql2": "^3.12.0",
"nodemon": "^3.1.9",
"sequelize": "^6.37.5",
"ts-node": "^10.9.2",
"typescript": "^5.7.3"
}
}
```
src\server.ts
```typescript
import app from "./app";
const PORT = process.env.PORT || 3000;
app.listen(PORT,()=> {
console.log(`http://localhost:${PORT}/api`);
})
```
src\app.ts
```typescript
import express from "express";
import userRouter from "./routes/userRoutes";
const app = express();
app.use(express.json());
app.use("/api",userRouter);
export default app;
```
src\routes\userRoutes.ts
```typescript
import { Router } from "express";
import { getUserById, getUsers, createUser, updateUser } from "../controllers/userController";
const userRouter = Router();
userRouter.get("/users", getUsers);
userRouter.get("/users/:id", getUserById);
userRouter.post("/create", createUser);
userRouter.put("/update/:id", updateUser);
export default userRouter;
```
src\models\userModel.ts
```typescript
import { DataTypes, Model } from "sequelize";
import sequelize from "../config/database";
class User extends Model {
public id!: string;
public nome!: string;
public email!: string;
public idade?: number;
public ativo!: boolean;
}
User.init(
{
id: {
type: DataTypes.UUID,
primaryKey: true,
unique: true
},
nome: {
type: DataTypes.STRING
},
email: {
type: DataTypes.STRING,
unique: true
},
idade: {
type: DataTypes.NUMBER
},
ativo: {
type: DataTypes.BOOLEAN
}
},
{
sequelize,
tableName: "users"
}
);
export default User;
```
src\controllers\userController.ts
```typescript
import { Request, Response } from "express";
import User from "../models/userModel";
export const getUsers = async (req: Request, res: Response): Promise => {
try {
const users = await User.findAll();
res.send(users);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const getUserById = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const user = await User.findByPk(id);
res.send(user);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const createUser = async (req: Request, res: Response): Promise => {
try {
const { nome, email, idade, ativo } = req.body;
const user = await User.create({nome,email,idade,ativo});
res.send(user);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
export const updateUser = async (req: Request, res: Response): Promise => {
try {
const { id } = req.params;
const { nome, email, idade, ativo } = req.body;
const user = await User.findByPk(id);
const userUp = await user?.update({ nome, email, idade, ativo })
res.send(userUp);
} catch (error) {
res.status(500).json({ message: 'Erro ao buscar usuários', details: (error as Error).message });
}
}
```
src\config\database.ts
```typescript
import { Sequelize } from "sequelize";
const sequelize = new Sequelize(
"database_test",
"root",
"",
{
host: "localhost",
dialect: "mysql"
}
);
export default sequelize;
```
## Example 2
Giống với Laravel cũng có những thuật ngữ phải nhớ
```actionscript
The A.hasOne(B) association means that a One - To - One relationship exists between A and B, with the foreign key being defined in the target model(B).
The A.belongsTo(B) association means that a One - To - One relationship exists between A and B, with the foreign key being defined in the source model(A).
The A.hasMany(B) association means that a One - To - Many relationship exists between A and B, with the foreign key being defined in the target model(B).
These three calls will cause Sequelize to automatically add foreign keys to the appropriate models(unless they are already present).
The A.belongsToMany(B, { through: 'C' }) association means that a Many - To - Many relationship exists between A and B, using table C as junction table, which will have the foreign keys(aId and bId, for example).Sequelize will automatically create this model C(unless it already exists) and define the appropriate foreign keys on it.
```
package.json
```json
{
"name": "graphql-example",
"version": "1.0.0",
"description": "GraphQL Example project for Toptal blog article",
"main": "index.js",
"repository": "ssh://git@github.com/amaurymartiny/graphql-example",
"author": "Amaury Martiny ",
"license": "MIT",
"semistandard": {
"env": "node"
},
"scripts": {
"start": "babel-node index.js",
"dev": "nodemon --exec babel-node index.js",
"lint": "semistandard --fix"
},
"dependencies": {
"@apollo/server": "^4.11.3",
"@graphql-tools/schema": "^10.0.16",
"apollo-server-express": "^3.13.0",
"babel-cli": "^6.26.0",
"babel-preset-es2015": "^6.24.1",
"body-parser": "^1.20.3",
"cors": "^2.8.5",
"express": "^4.21.2",
"graphql": "^16.10.0",
"graphql-server-express": "^1.4.1",
"graphql-tools": "^9.0.11",
"http": "^0.0.1-security",
"nodemon": "^3.1.9",
"path": "^0.12.7",
"semistandard": "^17.0.0",
"sequelize": "^6.37.5",
"sqlite3": "^5.1.7"
}
}
```
Operation.sql
```sql
query {
# users {
# id,
# firstname
# }
# user(id: 2) {
# firstname
# }
}
# query getUserWithProjects {
# user(id: 2) {
# firstname
# lastname
# projects {
# name
# tasks {
# description
# }
# }
# }
# }
mutation {
# createUser(input:{email: "lionel2@gmail.com",firstname: "lionel 2",lastname: "pham2"}) {
# email,
# firstname,
# lastname
# },
# updateUser(id:3,input: {firstname: "Lionel 1.3 Edit",lastname:"Pham 1.3 Edit", email: "lionel1.1@gmail.com"}) {
# firstname,
# lastname,
# email
# },
# removeUser(id: 10) {
# email
# }
# createProject(input: {name: "Project 2",UserId:1}) {
# name
# }
# updateProject(id:6,input: {name: "Project 2.2",UserId: 1}) {
# name
# }
# removeProject(id: 5) {
# name
# }
# createTask(input: {description: "Task 1",ProjectId: 1}) {
# description
# }
# updateTask(id: 9,input: {description: "Task 1 Edit",ProjectId: 1}) {
# description
# }
# removeTask(id: 9) {
# description
# }
}
```
index.js
```javascript
import express from 'express';
import { ApolloServer } from '@apollo/server';
import bodyParser from 'body-parser';
import cors from 'cors';
// import { graphqlExpress, graphiqlExpress } from 'graphql-server-express';
// import { makeExecutableSchema } from 'graphql-tools';
import { makeExecutableSchema } from '@graphql-tools/schema';
import { expressMiddleware } from '@apollo/server/express4';
import routes from './rest/routes';
import typeDefs from './graphql/typeDefs';
import resolvers from './graphql/resolvers';
import http from 'http';
const app = express();
const httpServer = http.createServer(app);
// Middlewares
app.use(bodyParser.json());
// Mount REST on /api
app.use('/api', routes);
// Mount GraphQL on /graphql
// const schema = makeExecutableSchema({
// typeDefs,
// resolvers: resolvers()
// });
const server = new ApolloServer({
typeDefs,
resolvers: resolvers()
});
async function test() {
await server.start();
// app.use('/graphql', graphqlExpress({ schema }));
// app.use('/graphiql', graphiqlExpress({ endpointURL: '/graphql' }));
// app.listen(3000, () => console.log('Express app listening on localhost:3000'));
app.use(
cors(),
bodyParser.json(),
expressMiddleware(server),
);
await new Promise((resolve) => httpServer.listen({ port: 3000 }, resolve));
console.log(`🚀 Server ready at http://localhost:3000`);
}
test();
```
rest\routes\user.routes.js
```javascript
import express from 'express';
import userController from '../controllers/user.controller';
const router = express.Router(); // eslint-disable-line new-cap
router.route('/')
/** GET /api/users - Get list of users */
.get(userController.list);
router.route('/:userId')
/** GET /api/users/:userId - Get user */
.get(userController.get);
router.route('/:userId/projects')
/** GET /api/users/:userId/projects - List projects of user */
.get(userController.listProjects);
/** Load user when API with userId route parameter is hit */
router.param('userId', userController.load);
export default router;
```
rest\routes\task.routes.js
```javascript
import express from 'express';
import taskController from '../controllers/task.controller';
const router = express.Router(); // eslint-disable-line new-cap
router.route('/')
/** GET /api/tasks - Get list of tasks */
.get(taskController.list);
router.route('/:taskId')
/** GET /api/tasks/:taskId - Get task */
.get(taskController.get);
/** Load task when API with taskId route parameter is hit */
router.param('taskId', taskController.load);
export default router;
```
rest\routes\project.routes.js
```javascript
import express from 'express';
import projectController from '../controllers/project.controller';
const router = express.Router(); // eslint-disable-line new-cap
router.route('/')
/** GET /api/projects - Get list of projects */
.get(projectController.list);
router.route('/:projectId')
/** GET /api/projects/:projectId - Get project */
.get(projectController.get);
/** Load project when API with projectId route parameter is hit */
router.param('projectId', projectController.load);
export default router;
```
rest\routes\index.js
```javascript
import express from 'express';
import userRoutes from './user.routes';
import projectRoutes from './project.routes';
import taskRoutes from './task.routes';
const router = express.Router(); // eslint-disable-line new-cap
router.use('/users', userRoutes);
router.use('/projects', projectRoutes);
router.use('/tasks', taskRoutes);
export default router;
```
rest\controllers\project.controller.js
```javascript
import sequelize from '../../models';
const Project = sequelize.models.Project;
/**
* Load Project and append to req.
*/
function load (req, res, next, id) {
Project.findOne({ id })
.then((Project) => {
req.Project = Project; // eslint-disable-line no-param-reassign
return next();
})
.catch(e => next(e));
}
/**
* Get Project list.
* @property {number} req.query.skip - Number of Projects to be skipped.
* @property {number} req.query.limit - Limit number of Projects to be returned.
* @returns {Project[]}
*/
function list (req, res, next) {
Project.findAll()
.then(Projects => res.json(Projects))
.catch(e => next(e));
}
/**
* Get Project
* @returns {Project}
*/
function get (req, res) {
return res.json(req.Project);
}
export default { load, get, list };
```
rest\controllers\task.controller.js
```javascript
import sequelize from '../../models';
const Task = sequelize.models.Task;
/**
* Load Task and append to req.
*/
function load (req, res, next, id) {
Task.findOne({ id })
.then((Task) => {
req.Task = Task; // eslint-disable-line no-param-reassign
return next();
})
.catch(e => next(e));
}
/**
* Get Task list.
* @property {number} req.query.skip - Number of Tasks to be skipped.
* @property {number} req.query.limit - Limit number of Tasks to be returned.
* @returns {Task[]}
*/
function list (req, res, next) {
Task.findAll()
.then(Tasks => res.json(Tasks))
.catch(e => next(e));
}
/**
* Get Task
* @returns {Task}
*/
function get (req, res) {
return res.json(req.Task);
}
export default { load, get, list };
```
rest\controllers\user.controller.js
```javascript
import sequelize from '../../models';
const User = sequelize.models.User;
/**
* Load user and append to req.
*/
function load(req, res, next, id) {
User.findByPk(id)
.then((user) => {
req.user = user;
return next();
})
.catch(e => next(e));
}
/**
* Get user list.
* @property {number} req.query.skip - Number of users to be skipped.
* @property {number} req.query.limit - Limit number of users to be returned.
* @returns {User[]}
*/
function list(req, res, next) {
User.findAll()
.then(users => res.json(users))
.catch(e => next(e));
}
/**
* Get user
* @returns {User}
*/
function get(req, res) {
return res.json(req.user);
}
/**
* List projects of user
* @returns {Projects[]}
*/
function listProjects(req, res, next) {
req.user.getProjects()
.then(projects => res.json(projects))
.catch(e => next(e));
}
export default { load, get, list, listProjects };
```
models\user.model.js
```javascript
import {Sequelize} from 'sequelize';
export default function (sequelize) {
const User = sequelize.define('User', {
firstname: Sequelize.STRING,
lastname: Sequelize.STRING,
email: Sequelize.STRING
}, {
createdAt: false,
updatedAt: false
});
User.associate = (models) => {
User.hasMany(models.Project);
};
}
```
models\task.model.js
```javascript
import {Sequelize} from 'sequelize';
export default function (sequelize) {
const Task = sequelize.define('Task', {
description: Sequelize.STRING
}, {
createdAt: false,
updatedAt: false
});
Task.associate = (models) => {
Task.belongsTo(models.Project);
};
}
```
models\seed.js
```javascript
// Add some data in the database
export default function (sequelize) {
const models = sequelize.models;
models.User.create({
firstname: 'John',
lastname: 'Doe',
email: 'john.doe@example.com'
})
.then((user) => models.Project.create({
name: 'Migrate from REST to GraphQL',
UserId: user.id
}))
.then((project) => {
models.Task.create({
description: 'Read tutorial',
ProjectId: project.id
});
models.Task.create({
description: 'Start coding',
ProjectId: project.id
});
return Promise.resolve(project);
})
.then((project) => models.Project.create({
name: 'Create a blog',
UserId: project.UserId
}))
.then((project) => {
models.Task.create({
description: 'Write draft of article',
ProjectId: project.id
});
models.Task.create({
description: 'Set up blog platform',
ProjectId: project.id
});
return Promise.resolve();
})
.then(() => models.User.create({
firstname: 'Alicia',
lastname: 'Smith',
email: 'alicia.smith@example.com'
}))
.then((user) => models.Project.create({
name: 'Email Marketing Campaign',
UserId: user.id
}))
.then((project) => {
models.Task.create({
description: 'Get list of users',
ProjectId: project.id
});
models.Task.create({
description: 'Write email template',
ProjectId: project.id
});
return Promise.resolve(project);
})
.then((project) => models.Project.create({
name: 'Hire new developer',
UserId: project.UserId
}))
.then((project) => {
models.Task.create({
description: 'Find candidates',
ProjectId: project.id
});
models.Task.create({
description: 'Prepare interview',
ProjectId: project.id
});
return Promise.resolve();
});
}
```
models\project.model.js
```javascript
import {Sequelize} from 'sequelize';
export default function (sequelize) {
const Project = sequelize.define('Project', {
name: Sequelize.STRING
}, {
createdAt: false,
updatedAt: false
});
Project.associate = (models) => {
Project.belongsTo(models.User);
Project.hasMany(models.Task);
};
}
```
models\index.js
```javascript
import { Sequelize } from 'sequelize';
import User from './user.model';
import Project from './project.model';
import Task from './task.model';
import seed from './seed'; // eslint-disable-line
import path from 'path';
const sequelize = new Sequelize(
"db",
process.env.USER,
process.env.PASSWORD,
{
host: "0.0.0.0",
dialect: 'sqlite',
pool: {
max: 5,
min: 0,
idle: 10000
},
storage: path.resolve('db', 'db.sqlite'),
logging: false
}
);
sequelize.authenticate()
.then(() => {
console.log('Connection has been established successfully.');
})
.catch(err => {
console.error('Unable to connect to the database:', err);
});
User(sequelize);
Project(sequelize);
Task(sequelize);
// Set up data relationships
const models = sequelize.models;
Object.keys(models).forEach(name => {
if ('associate' in models[name]) {
models[name].associate(models);
}
});
sequelize.sync();
// Uncomment the line if you want to rerun DB seed
// sequelize.sync({ force: true }).then(() => seed(sequelize));
export default sequelize;
```
graphql\typeDefs.js
```javascript
const typeDefinitions = `
type User {
id: ID!
firstname: String
lastname: String
email: String
projects: [Project]
}
input UserInput {
firstname: String
lastname: String
email: String
}
type Project {
id: ID!
name: String
tasks: [Task]
}
input ProjectInput {
name: String
UserId: ID!
}
type Task {
id: ID!
description: String
ProjectId: ID!
}
input TaskInput {
description: String
ProjectId: ID!
}
# The schema allows the following queries:
type RootQuery {
user(id: ID): User
users: [User]
project(id: ID!): Project
projects: [Project]
task(id: ID!): Task
tasks: [Task]
}
# The schema allows the following mutations:
type RootMutation {
createUser(input: UserInput!): User
updateUser(id: ID!, input: UserInput!): User
removeUser(id: ID!): User
createProject(input: ProjectInput!): Project
updateProject(id: ID!, input: ProjectInput!): Project
removeProject(id: ID!): Project
createTask(input: TaskInput!): Task
updateTask(id: ID!, input: TaskInput!): Task
removeTask(id: ID!): Task
}
# We need to tell the server which types represent the root query.
# We call them RootQuery and RootMutation by convention.
schema {
query: RootQuery
mutation: RootMutation
}
`;
export default typeDefinitions;
```
graphql\resolvers.js
```javascript
import sequelize from '../models';
export default function resolvers() {
const models = sequelize.models;
return {
RootQuery: {
user(root, { id }) {
return models.User.findByPk(id);
},
users(root) {
return models.User.findAll({});
},
},
RootMutation: {
createUser (root, { input }) {
return models.User.create(input);
},
updateUser (root, { id, input }) {
models.User.update(input, {where: { id } });
return models.User.findByPk(id);
},
removeUser (root, { id }) {
return models.User.destroy({where: { id } });
},
createProject(root, { input }) {
return models.Project.create(input);
},
updateProject(root, {id, input}) {
models.Project.update(input, {where: { id } });
return models.Project.findByPk(id);
},
removeProject(root,{id}) {
return models.Project.destroy({where: { id } });
},
createTask(root,{input}) {
return models.Task.create(input);
},
updateTask(root, {id,input}) {
models.Task.update(input, {where: { id } });
return models.Task.findByPk(id);
},
removeTask(root, {id}) {
return models.Task.destroy({where: { id } });
}
},
User: {
projects(user) {
return user.getProjects();
}
},
Project: {
tasks(project) {
return project.getTasks();
}
}
};
}
```
C:\Users\Administrator\Desktop\graphql-example\db\db.sqlite
{% file src="/files/y58YFO336rISJKqXK8Ih" %}
## graphql-example
{% file src="/files/eBqIcBDbqAt5XcdGNfmc" %}
GraphQL Example project for Toptal blog article:
### Getting Started
```
git clone https://github.com/amaurymartiny/graphql-example
cd graphql-example
npm install
npm run dev
```
You should be able to see the app running at [http://localhost:3000](http://localhost:3000/).
### Information
* The `models` folder contains the three models: User, Project and Task. They are created using the `sequelize` ORM.
* The `rest` folder contains the logic to create the associated `/api/users`, `/api/projects` and `/api/tasks` endpoints.
* The `graphql` folder contains the schema and resolvers for GraphQL.
* `db.sqlite` contains the database.
* `index.js` starts the Express server.
### Demo
This example project is hosted on Heroku.
* The rest endpoints can be viewed here
*
*
*
* The GraphQL endpoint is , and a GraphiQL interface is mounted [here](http://graphql-example.herokuapp.com/graphiql).
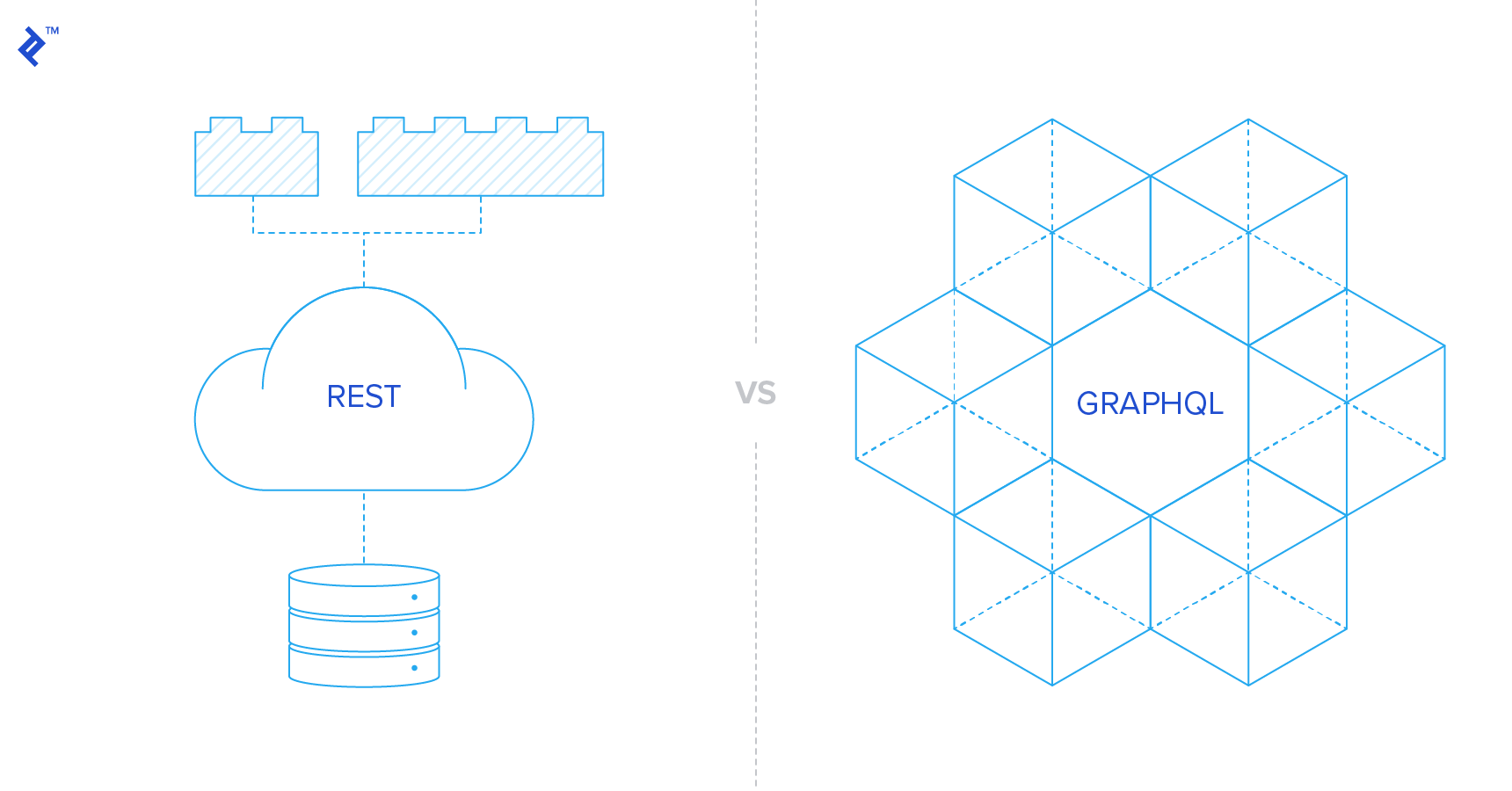
You might have heard about the new kid around the block: GraphQL. If not, GraphQL is, in a word, a new way to fetch [APIs](https://www.toptal.com/api-developers), an alternative to REST. It started as an internal project at Facebook, and since it was open sourced, it has gained [a lot of traction](https://trends.google.com/trends/explore?date=today%205-y\&q=graphql).
The aim of this article is to help you make an easy transition from REST to GraphQL, whether you’ve already made your mind for GraphQL or you’re just willing to give it a try. No prior knowledge of GraphQL is needed, but some familiarity with REST APIs is required to understand the article.
The first part of the article will start by giving three reasons why I personally think GraphQL is superior to REST. The second part is a tutorial on how to add a GraphQL endpoint on your back-end.
### GraphQL vs. REST: Why Drop REST?
If you are still hesitating on whether or not GraphQL is suited for your needs, a quite extensive and objective overview of “REST vs. GraphQL” is given [here](https://philsturgeon.uk/api/2017/01/24/graphql-vs-rest-overview/). However, for my top three reasons to use GraphQL, read on.
#### Reason 1: Network Performance
Say you have a user resource on the back-end with first name, last name, email, and 10 other fields. On the client, you generally only need a couple of those.
Making a REST call on the `/users` endpoint gives you back all the fields of the user, and the client only uses the ones it needs. There is clearly some data transfer waste, which might be a consideration on mobile clients.
GraphQL by default fetches the smallest data possible. If you only need first and last names of your users, you specify that in your query.
The interface below is called GraphiQL, which is like an API explorer for GraphQL. I created a small project for the purpose of this article. The code is hosted [on GitHub](https://github.com/amaurymartiny/graphql-example), and we’ll dive into it in the second part.
On the left pane of the interface is the query. Here, we are fetching all the users—we would do `GET /users` with REST—and only getting their first and last names.
**Query**
```fsharp
query {
users {
firstname
lastname
}
}
```
**Result**
```prolog
{
"data": {
"users": [
{
"firstname": "John",
"lastname": "Doe"
},
{
"firstname": "Alicia",
"lastname": "Smith"
}
]
}
}
```
If we wanted to get the emails as well, adding an “email” line below “lastname” would do the trick.
Some REST back-ends do offer options like `/users?fields=firstname,lastname` to return partial resources. For what it’s worth, [Google recommends it](https://developers.google.com/google-apps/tasks/performance#partial). However, it is not implemented by default, and it makes the request barely readable, especially when you toss in other query parameters:
* `&status=active` to filter active users
* `&sort=createdAat` to sort the users by their creation date
* `&sortDirection=desc` because you obviously need it
* `&include=projects` to include the users’ projects
These query parameters are patches added to the REST API to imitate a query language. GraphQL is above all a query language, which makes requests concise and precise from the beginning.
#### Reason 2: The “Include vs. Endpoint” Design Choice
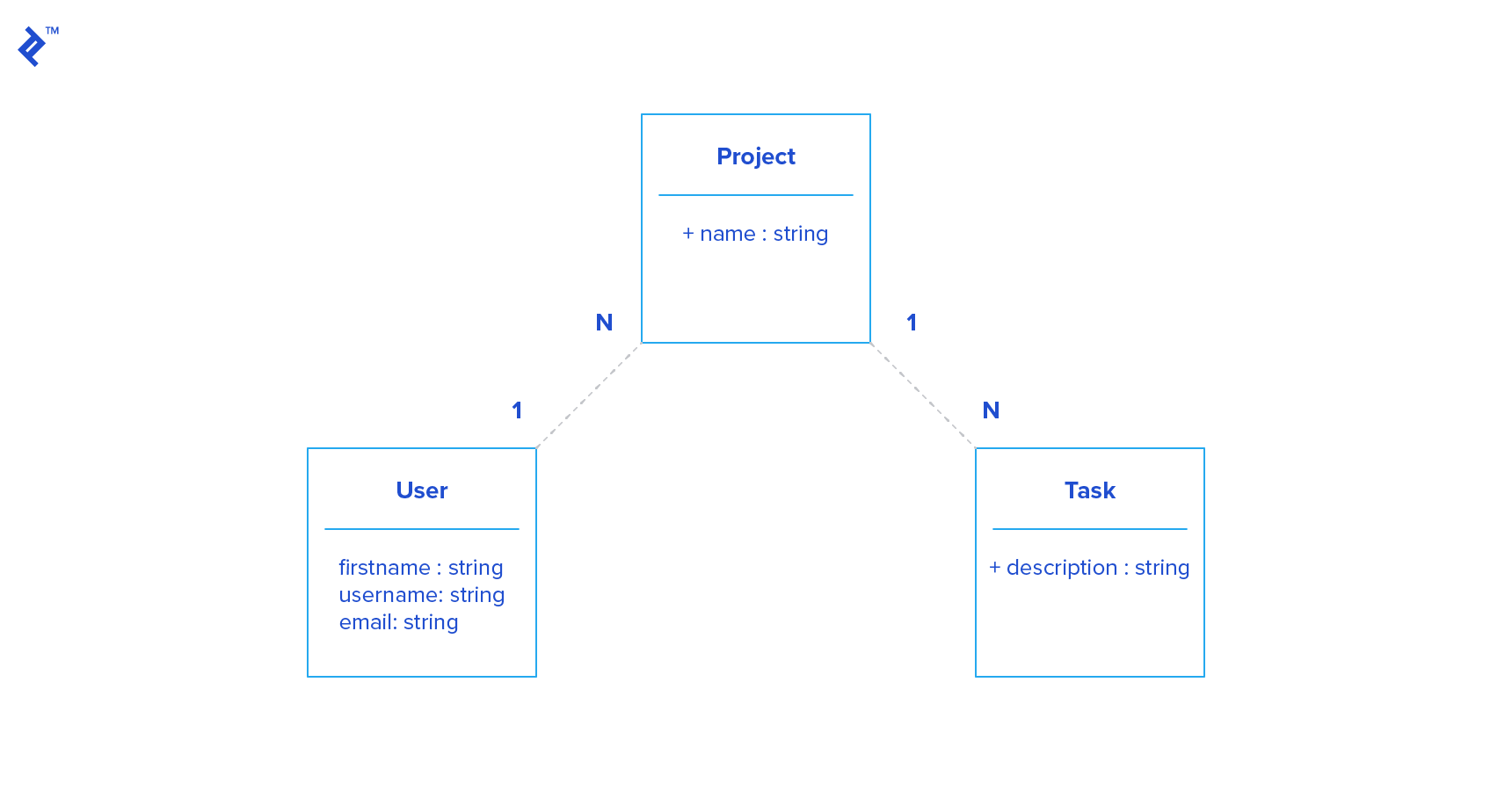
Let’s imagine we want to build a simple project management tool. We have three resources: users, projects, and tasks. We also define the following relationships between the resources:
Here are some of the endpoints we expose to the world:
| Endpoint | Description |
| ------------------------- | ------------------------------- |
| `GET /users` | List all users |
| `GET /users/:id` | Get the single user with id :id |
| `GET /users/:id/projects` | Get all projects of one user |
The endpoints are simple, easily readable, and well-organized.
Things get trickier when our requests get more complex. Let’s take the `GET /users/:id/projects` endpoint: Say I want to show only the projects’ titles on the home page, but projects+tasks on the dashboard, without making multiple REST calls. I would call:
* `GET /users/:id/projects` for the home page.
* `GET /users/:id/projects?include=tasks` (for example) on the dashboard page so that the back-end appends all related tasks.
It’s common practice to add query parameters `?include=...` to make this work, and is even recommended by the [JSON API](http://jsonapi.org/) specification. Query parameters like `?include=tasks` are still readable, but before long, we will end up with `?include=tasks,tasks.owner,tasks.comments,tasks.comments.author`.
In this case, would be it wiser to create a `/projects` endpoint to do this? Something like `/projects?userId=:id&include=tasks`, as we would have one level of relationship less to include? Or, actually, a `/tasks?userId=:id` endpoint might work too. This can be a difficult design choice, [even more complicated](https://stackoverflow.com/questions/6324547/how-to-handle-many-to-many-relationships-in-a-restful-api) if we have a many-to-many relationship.
GraphQL uses the `include` approach everywhere. This makes the syntax to fetch relationships powerful and consistent.
Here’s an example of fetching all projects and tasks from the user with id 1.
**Query**
```fsharp
{
user(id: 1) {
projects {
name
tasks {
description
}
}
}
}
```
**Result**
```prolog
{
"data": {
"user": {
"projects": [
{
"name": "Migrate from REST to GraphQL",
"tasks": [
{
"description": "Read tutorial"
},
{
"description": "Start coding"
}
]
},
{
"name": "Create a blog",
"tasks": [
{
"description": "Write draft of article"
},
{
"description": "Set up blog platform"
}
]
}
]
}
}
}
```
As you can see, the query syntax is easily readable. If we wanted to go deeper and include tasks, comments, pictures, and authors, we wouldn’t think twice about how to organize our API. GraphQL makes it easy to fetch complex objects.
#### Reason 3: Managing Different Types of Clients
When building a back-end, we always start by trying to make the API as widely usable by all clients as possible. Yet clients always want to call less and fetch more. With deep includes, partial resources, and filtering, requests made by web and mobile clients may differ a lot one from another.
With REST, there are a couple of solutions. We can create a custom endpoint (i.e., an alias endpoint, e.g., `/mobile_user`), a custom representation (`Content-Type: application/vnd.rest-app-example.com+v1+mobile+json`), or even a client-specific API (like [Netflix once did](https://medium.com/netflix-techblog/embracing-the-differences-inside-the-netflix-api-redesign-15fd8b3dc49d)). All three of them require extra effort from the back-end development team.
GraphQL gives more power to the client. If the client needs complex requests, it will build the corresponding queries itself. Each client can consume the same API differently.
### How to Start with GraphQL
In most debates about “GraphQL vs. REST” today, people think that they must choose either one of the two. This is simply not true.
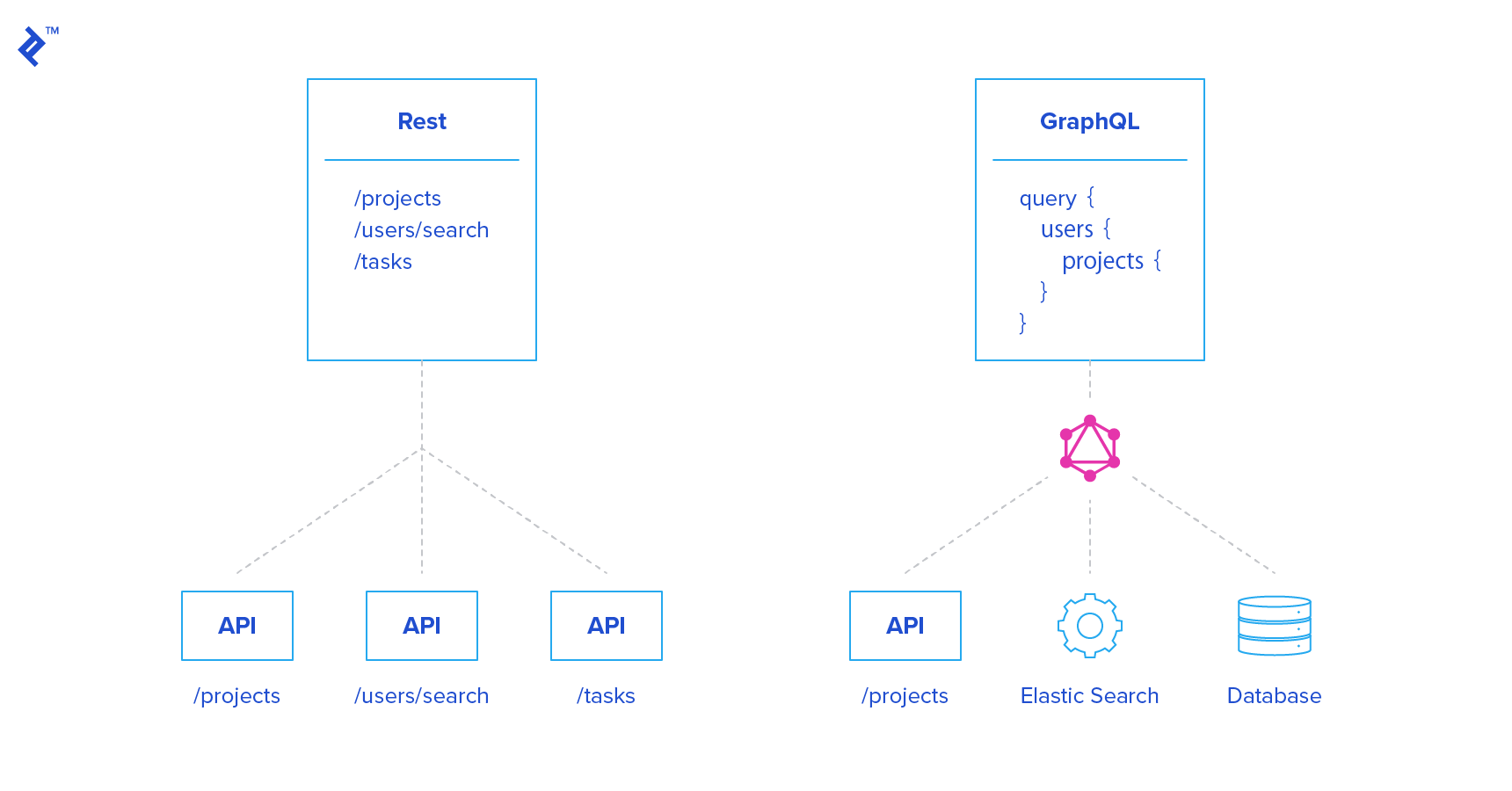
Modern applications generally use several different services, which expose several APIs. We could actually think of GraphQL as a gateway or a wrapper to all these services. All clients would hit the GraphQL endpoint, and this endpoint would hit the database layer, an external service like ElasticSearch or Sendgrid, or other REST endpoints.
A second way of using both is to have a separate `/graphql` endpoint on your REST API. This is especially useful if you already have numerous clients hitting your REST API, but you want to try GraphQL without compromising the existing infrastructure. And this is the solution we are exploring today.
As said earlier, I will illustrate this tutorial with a small example project, available [on GitHub](https://github.com/amaurymartiny/graphql-example). It is a simplified project management tool, with users, projects, and tasks.
The technologies used for this project are Node.js and Express for the web server, SQLite as the relational database, and Sequelize as an ORM. The three models—user, project, and task—are defined in the [`models`](https://github.com/amaurymartiny/graphql-example/tree/master/models) folder. The REST endpoints `/api/users`\*, `/api/projects`\* and `/api/tasks`\* are exposed to the world, and are defined in the [`rest`](https://github.com/amaurymartiny/graphql-example/tree/master/rest) folder.
\* *Note: After publication, Heroku stopped offering free hosting, and the demos are no longer available.*
Do note that GraphQL can be installed on any type of back-end and database, using any programming language. The technologies used here are chosen for the sake of simplicity and readability.
Our goal is to create a `/graphql` endpoint without removing the REST endpoints. The GraphQL endpoint will hit the database ORM directly to fetch data, so that it is totally independant from the REST logic.
#### Types
The data model is represented in GraphQL by **types**, which are strongly typed. There should be a 1-to-1 mapping between your models and GraphQL types. Our `User` type would be:
```elm
type User {
id: ID! # The "!" means required
firstname: String
lastname: String
email: String
projects: [Project] # Project is another GraphQL type
}
```
#### Queries
**Queries** define what queries you can run on your GraphQL API. By convention, there should be a `RootQuery`, which contains all the existing queries. I also pointed out the REST equivalent of each query:
```elm
type RootQuery {
user(id: ID): User # Corresponds to GET /api/users/:id
users: [User] # Corresponds to GET /api/users
project(id: ID!): Project # Corresponds to GET /api/projects/:id
projects: [Project] # Corresponds to GET /api/projects
task(id: ID!): Task # Corresponds to GET /api/tasks/:id
tasks: [Task] # Corresponds to GET /api/tasks
}
```
#### Mutations
If queries are `GET` requests, **mutations** can be seen as `POST`/`PATCH`/`PUT`/`DELETE` requests (although really they are synchronized versions of queries).
By convention, we put all our mutations in a `RootMutation`:
```elm
type RootMutation {
createUser(input: UserInput!): User # Corresponds to POST /api/users
updateUser(id: ID!, input: UserInput!): User # Corresponds to PATCH /api/users
removeUser(id: ID!): User # Corresponds to DELETE /api/users
createProject(input: ProjectInput!): Project
updateProject(id: ID!, input: ProjectInput!): Project
removeProject(id: ID!): Project
createTask(input: TaskInput!): Task
updateTask(id: ID!, input: TaskInput!): Task
removeTask(id: ID!): Task
}
```
Note that we introduced new types here, called `UserInput`, `ProjectInput`, and `TaskInput`. This is a common practice with REST too, to create an input data model for creating and updating resources. Here, our `UserInput` type is our `User` type without the `id` and `projects` fields, and notice the keyword `input` instead of `type`:
```dts
input UserInput {
firstname: String
lastname: String
email: String
}
```
#### Schema
With types, queries and mutations, we define the **GraphQL schema**, which is what the GraphQL endpoint exposes to the world:
```dts
schema {
query: RootQuery
mutation: RootMutation
}
```
This schema is strongly typed and is what allowed us to have those handy autocompletes in GraphiQL\*.
\* *Note: After publication, Heroku stopped offering free hosting, and the demos for this article are no longer available.*
#### Resolvers
Now that we have the public schema, it is time to tell GraphQL what to do when each of these queries/mutations is requested. **Resolvers** do the hard work; they can, for example:
* Hit an internal REST endpoint
* Call a microservice
* Hit the database layer to do CRUD operations
We are choosing the third option in our example app. Let’s have a look at our [resolvers file](https://github.com/amaurymartiny/graphql-example/blob/master/graphql/resolvers.js):
```javascript
const models = sequelize.models;
RootQuery: {
user (root, { id }, context) {
return models.User.findById(id, context);
},
users (root, args, context) {
return models.User.findAll({}, context);
},
// Resolvers for Project and Task go here
},
/* For reminder, our RootQuery type was:
type RootQuery {
user(id: ID): User
users: [User]
# Other queries
}
```
This means, if the `user(id: ID!)` query is requested on GraphQL, then we return `User.findById()`, which is a Sequelize ORM function, from the database.
What about joining other models in the request? Well, we need to define more resolvers:
```javascript
User: {
projects (user) {
return user.getProjects(); // getProjects is a function managed by Sequelize ORM
}
},
/* For reminder, our User type was:
type User {
projects: [Project] # We defined a resolver above for this field
# ...other fields
}
*/
```
So when we request the `projects` field in a `User` type in GraphQL, this join will be appended to the database query.
And finally, resolvers for mutations:
```javascript
RootMutation: {
createUser (root, { input }, context) {
return models.User.create(input, context);
},
updateUser (root, { id, input }, context) {
return models.User.update(input, { ...context, where: { id } });
},
removeUser (root, { id }, context) {
return models.User.destroy(input, { ...context, where: { id } });
},
// ... Resolvers for Project and Task go here
}
```
You can play around with this here. For the sake of keeping the data on the server clean, I disabled the resolvers for mutations, which means that the mutations will not do any create, update or delete operations in the database (and thus return `null` on the interface).
**Query**
```fsharp
query getUserWithProjects {
user(id: 2) {
firstname
lastname
projects {
name
tasks {
description
}
}
}
}
mutation createProject {
createProject(input: {name: "New Project", UserId: 2}) {
id
name
}
}
```
**Result**
```prolog
{
"data": {
"user": {
"firstname": "Alicia",
"lastname": "Smith",
"projects": [
{
"name": "Email Marketing Campaign",
"tasks": [
{
"description": "Get list of users"
},
{
"description": "Write email template"
}
]
},
{
"name": "Hire new developer",
"tasks": [
{
"description": "Find candidates"
},
{
"description": "Prepare interview"
}
]
}
]
}
}
}
```
It may take some time to rewrite all types, queries, and resolvers for your existing app. However, a lot of tools exist to help you. For instance, [there ](https://github.com/postgraphql/postgraphql)[are ](https://github.com/mickhansen/graphql-sequelize)[tools](https://github.com/rexxars/sql-to-graphql) that translate a SQL schema to a GraphQL schema, including resolvers!
#### Putting Everything Together
With a well-defined schema and resolvers on what to do on each query of the schema, we can mount a `/graphql` endpoint on our back-end:
```javascript
// Mount GraphQL on /graphql
const schema = makeExecutableSchema({
typeDefs, // Our RootQuery and RootMutation schema
resolvers: resolvers() // Our resolvers
});
app.use('/graphql', graphqlExpress({ schema }));
```
And we can have a nice-looking GraphiQL interface\* on our back-end. To make a request without GraphiQL, simply copy the URL of the request (i.e., `https://host/graphql?query=query%20%7B%0A%20%20user(id%3A%202)%20%7B%0A%20%20%20%20firstname%0A%20%20%20%20lastname%0A%20%20%20%20projects%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%20%20tasks%20%7B%0A%20%20%20%20%20%20%20%20description%0A%20%20%20%20%20%20%7D%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D`\*), and run it with cURL, AJAX, or directly in the browser. Of course, there are some GraphQL clients to help you build these queries. See below for some examples.
\* *Note: After publication, Heroku stopped offering free hosting, and the demos are no longer available.*
### What’s Next?
This article’s aim is to give you a taste of what GraphQL looks like and show you that it’s definitely possible to try GraphQL without throwing away your REST infrastructure. The best way to know if GraphQL suits your needs is to try it yourself. I hope that this article will make you take the dive.
There are a lot of features we haven’t discussed about in this article, such as real-time updates, server-side batching, authentication, authorization, client-side caching, file uploading, etc. An excellent resource to learn about these features is [How to GraphQL](https://www.howtographql.com/).
Below are some other useful resources:
| Server-side Tool | Description |
| -------------------------------------------------------------------- | -------------------------------------------------------------------------------------------------- |
| [`graphql-js`](https://github.com/graphql/graphql-js) | The reference implementation of GraphQL. You can use it with `express-graphql` to create a server. |
| [`graphql-server`](https://dev.apollodata.com/tools/graphql-server/) | An all-in-one GraphQL server created by the [Apollo team](https://www.apollodata.com/). |
| [Implementations for other platforms](https://graphql.org/code/) | Ruby, PHP, etc. |
| Client-side Tool | Description |
| ---------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| [Relay](https://github.com/facebook/relay) | A framework for connecting React with GraphQL. |
| [apollo-client](https://github.com/apollographql/apollo-client). | A GraphQL client with bindings for [React](https://dev.apollodata.com/react/), [Angular 2](https://dev.apollodata.com/angular2/), and [other front-end frameworks](https://github.com/apollographql/apollo-client#learn-how-to-use-apollo-client-with-your-favorite-framework). |
In conclusion, I believe that GraphQL is more than hype. It won’t replace REST tomorrow just yet, but it does offer a performant solution to a genuine problem. It is relatively new, and best practices are still developing, but it is definitely a technology that we will hear about in the next couple of years.